
Prerequisites for Evolutionary Architectures
Designing software that is flexible and changeable is arguably the most important architectural property. I often get other software architects saying “What about performance?” or “What about security?” I’m not saying these other properties are not important to consider early on. They are. However, if we optimise our architecture for change (evolvability), when we discover a performance issue or a security vulnerability we can change our system to help address it. The ability to respond quickly to issues like these is exactly what makes evolutionary architecture so essential.
What properties are important in evolution?
You can think of the way a species adapts to its environment in the same way that you think of evolutionary architecture. To be successful, animals need to produce new generations with advantageous traits, respond to feedback from the environment, and leave room for failure by falling back on what works.
Software is similar. You need to make sure it’s adaptable and that you’re making changes to your system based on what works. There are a few key ways that we can create these adaptable architectures: Pick constraints to support rapid change
- Separate the concepts of deployment from release
- Gather and share fast (appropriate) feedback
- In development
- In production
- Build a responsive culture
Pick your constraints to support changeability
In order to support evolution in software we need to be aware of the constraints of the software and the environment that the software operates in.
As software architects and developers we have control over some aspects of the environment we build and run software in. Here are some of the constraints we might want to consider to support change/evolution.
Pick the right building materials
At the start of my career, I believed that any Turing complete programming language was equivalent to any other and the language picked was not that important. As I’ve become exposed to more programming languages, paradigms, libraries, and frameworks I’ve realised that the ‘building materials’ we pick have a huge impact on the inherent properties of our software systems, especially on changeability.
When you start building a new system, consider the following:
- Favour languages, libraries, and approaches that allow you to parse the data you need from larger more complex structures.
- If you are using a strongly statically typed language consider using a language that infers type to reduce changes you need to make through your code base.
- If you use a weakly typed language, think about what libraries or idioms you may need to add constraints on the types of changes allowed and how they can occur (otherwise you are in the wild west and anything goes)
- Favour immutable data structures - immutability constrains the way state can change in your executing program thus simplifying reasoning about state, especially in a multi threaded environment. If your language doesn’t support immutable data structures as the default there are plenty of libraries out there for most languages (look for persistent immutable data structures that reuse memory).
- Favour declarative approaches over imperative ones.
- Do you understand the problem well enough to pick a framework early on or should you maintain the flexibility by constructing your solution using small libraries? Pick tools and approaches to support feedback and deployment
In order to evolve, our software needs to be easy and quick to release, and we need feedback about it’s appropriateness during development and while in production. Therefore we should pick tooling and approaches that support those properties. Here’s a non-exhaustive list of some things to consider:
- Continuous integration
- Continuous delivery
- Dark deployments
- Canary deployments
- Blue/green deployments
- Automated testing
- Automated alerting/monitoring
Though it may sound frightening, it can be useful to incorporate production-testing alongside these other testing methodologies. Sometimes testing less and allowing something to alert if it fails can be a risk worth taking or even be advantageous in detecting the actual problem in production. Production is the only real test environment. However, this is a risk judgement dependent on the problem, architecture etc.
Implementing some or all of these approaches can enable you to respond to a bug by fixing forward fast rather than taking a more defensive approach of testing excessively and reverting if a bug occurs.
Stay small as long as possible
For every additional person involved in writing a system, you exponentially increase the communication paths on your team. If you can keep your teams and the number of teams as small as practical you reduce the amount of communication and coordination required to implement each change.
I would extend this principle to keeping the number of teams as small as possible too. Working with a constraint of a limited number of (the right) people will result in innovative approaches to solutions. Just make sure that one of them is not to work longer hours (therefore consider an upper limit on working hours as another constraint!).
Organisation-wide systems thinking
Even the most ‘brick and mortar’ businesses do a lot if not the majority of their customer interactions via software (even if it’s B2B) and therefore your organisation should think of software as the primary means of revenue generation.
Forcing ‘project thinking’ onto software development is a bad idea. Trying to implement a number of ‘features’ to a deadline and budget is often necessary but if every change to your software happens this way then that short term focus never leads to longer term consideration of the product or platform and it’s quality properties.
You can use projects to manage budgets but always think about the product or platform when choosing what to implement.
Separate deployment from release
In order to evolve, our software has to generate a new ‘mutated’ generation. If you can deploy your changes in a canary deployment or even, depending on the change, a dark deployment you can test the change in the only realistic test environment, production.
Without mandating a specific architecture (e.g. microservices, event streaming, modular monolith) Domain Driven Development (DDD) and Event Storming are very useful in determining the boundaries of deployment units.
Don’t consider static modelling in isolation If you build a data, component or class model in isolation you often focus on the wrong attributes. For example, you can model hundreds of attributes about a student in a university but the bursary system probably only cares about identification, fees and payment information plus events that change the state of those attributes whereas student services care about much more personal information. Use the dynamic aspects of the system to guide what information is important to that context.
Thinking about events and flows often leads to discovering the components (deployment units) of the system. Each high level process that sends and/or receives a message is a potential component.
Here is a list of techniques that can be useful for separating deployment from release:
- Feature toggling
- Branch by abstractions
- Continuous Integration/Continuous Delivery
- Immutable servers – packaging aspects of the runtime environment in an immutable image makes deployment and rollback a much less risky proposition.
- Schema on Read DB’s – they make adding data in a deployment much easier provided you always ‘accrete’ (or add to) your schema.
- Consider always API ‘accretion’ – Always adding to your APIs and only logically deprecating functionality or data is easier for client applications to deal with and a ‘breaking’ change is really a new API so treat it that way. Think about how to deal with data returned if you don’t have full control over your clients and can’t trust they parse only the data they need (e.g. do all clients implement tolerant reader pattern?). This is where using GraphQL even in service to service calls can have benefits as it’s inherent constraints assume only returning what’s requested (and you get schema introspection).
Fast appropriate feedback
I like to think about software as ‘living’ inside increasing larger ecosystems in the same way that biological organisms do.
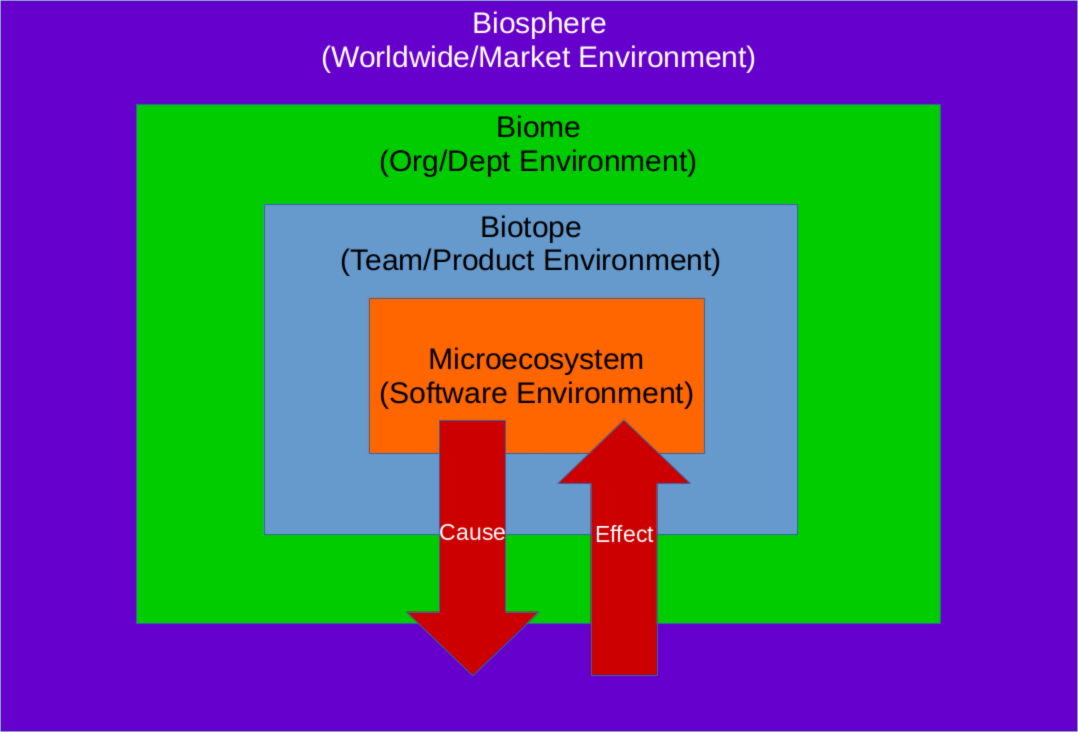
Illustration 1 shows the layers of ecosystems that our software ‘lives’ in. We can see from this illustration that the inner ecosystem can be affected by a change in one of the outer ecosystems but, conversely, the inner ecosystem can cause a change in the outer ecosystems.
Additionally not shown in this diagram is the concept of the frequency of the feedback.
- Software environment feedback is measured/sampled in microsecond/seconds/minutes/hours.
- Team/product environment feedback is likely to be measured/sampled in days or weeks.
- Organisational/departmental environment feedback is likely to be measured/sampled in weeks or months.
- World wide/market environment feedback is likely to be measured/sampled in quarters/bi-annually/annually.
Without going into an exhaustive list of metrics and techniques that might be used to provide feedback the following illustrations give you some ideas of what you might want to consider, but as always, there’s no silver bullet and YMMV.
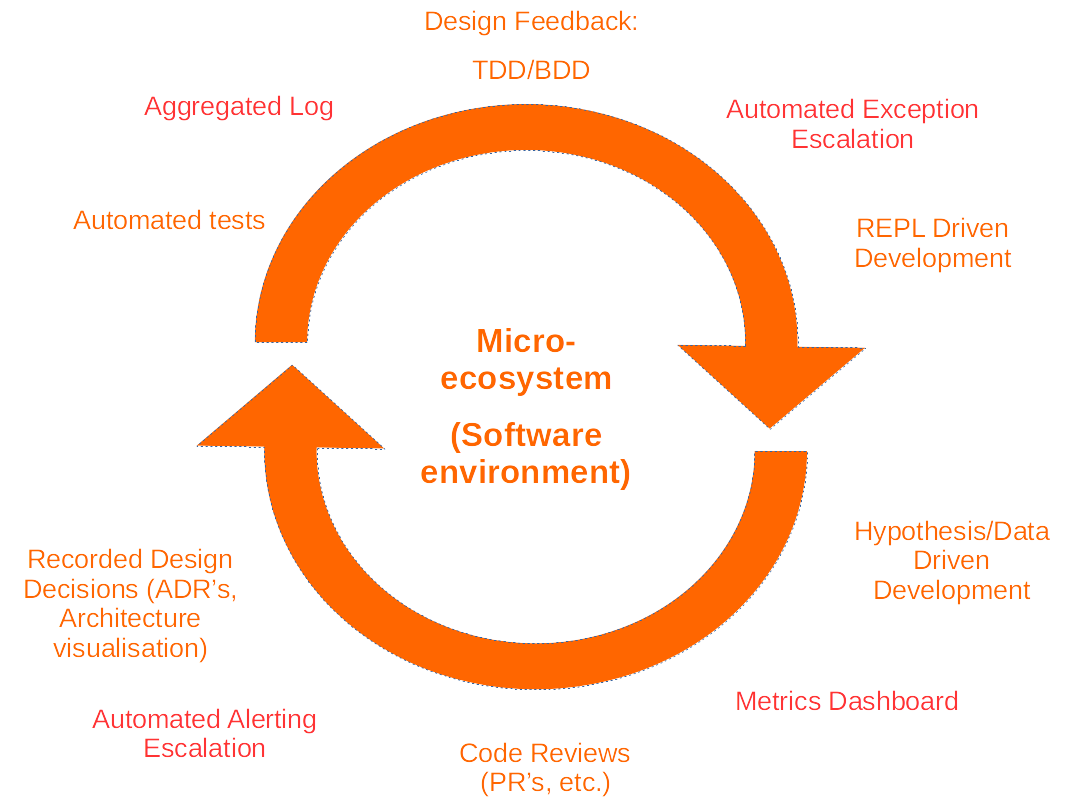
The micro-ecosystem translates to the runtime environment and the software development practices used in developing the software. The illustration above gives some metrics and techniques that can provide feedback at that level.
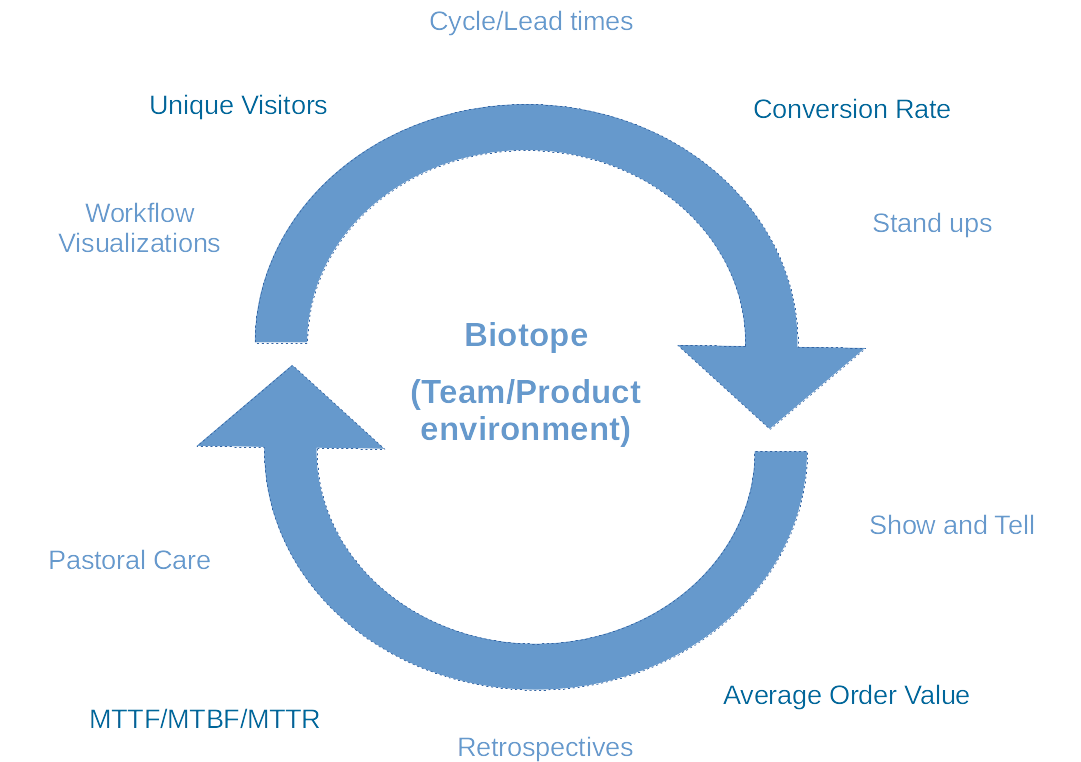
The biological concept of a Biotope (or habitat) translates to the team and/or product that the software is a part of and Illustration 3 gives some examples of metrics and techniques for feedback at this level.
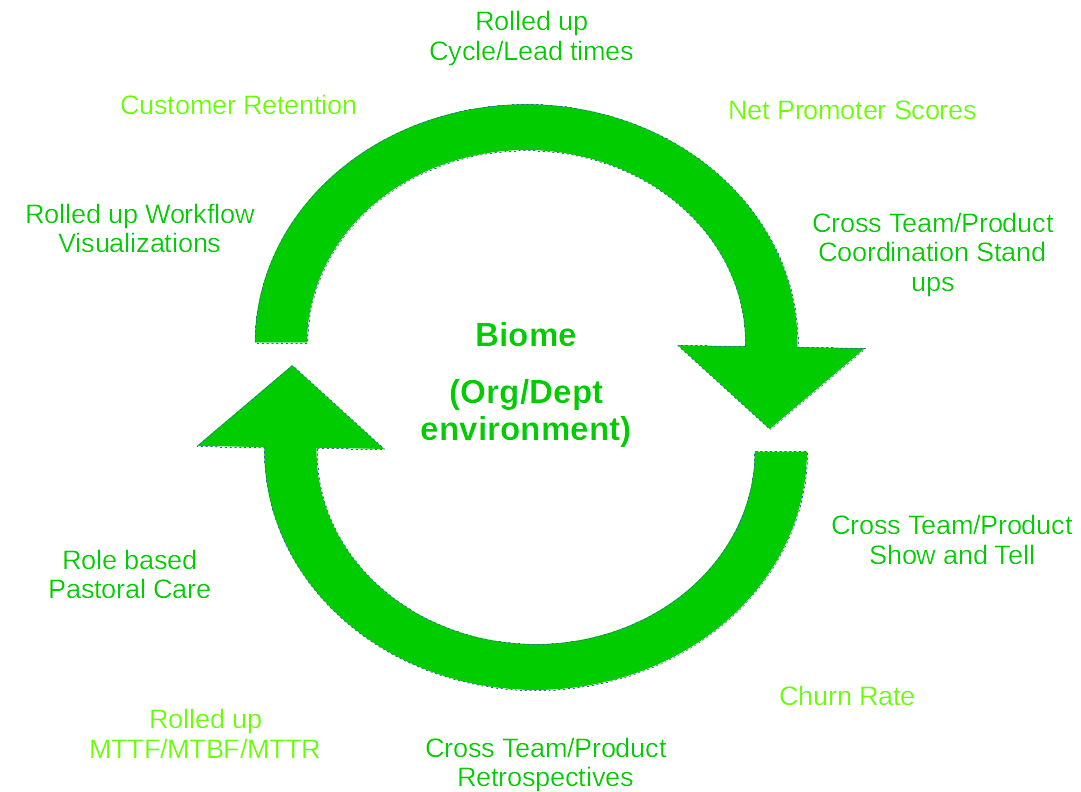
Illustration 4 shows some examples of metrics and techniques to provide feedback at the organisation or departmental level.
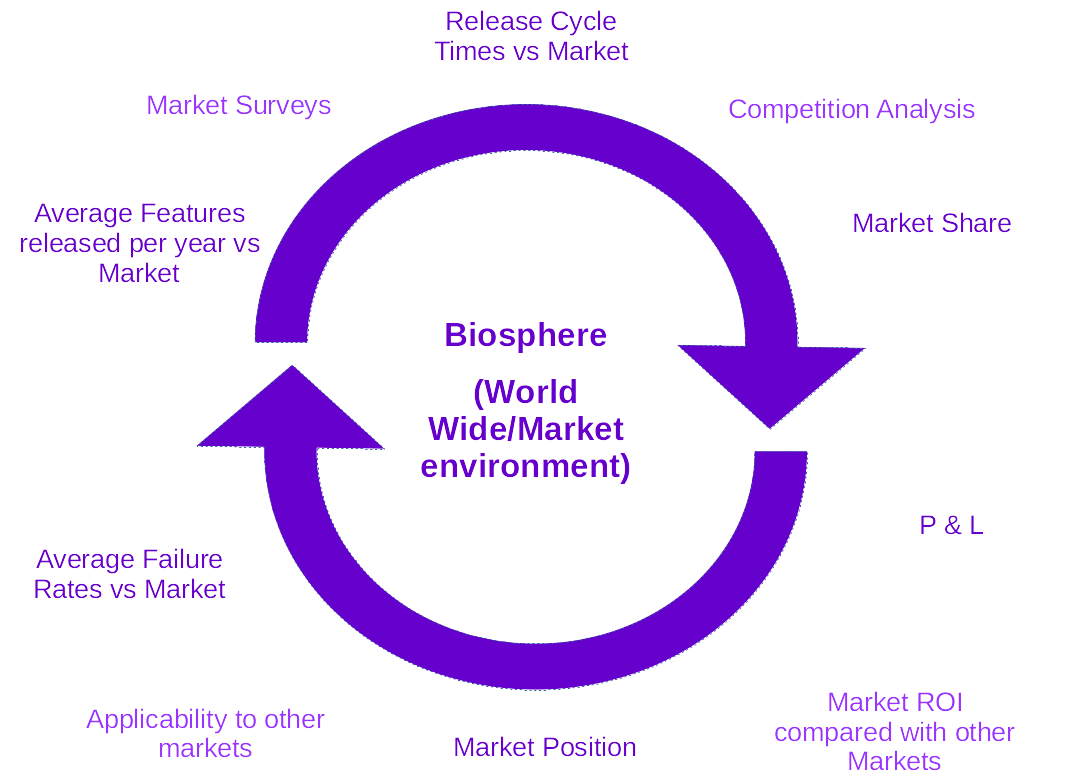
Finally, Illustration 5 gives examples of potential feedback mechanisms at the level of the target market or in other markets.
As you can see the example metrics I’ve suggested are a mix of measurements of the processes for producing/running software and the measurement of external factors that may impact or be impacted by that software. It’s important not to concentrate on only measuring the things you can change directly but also measure the factors that you only have indirect influence over to enable your software to evolve to those pressures too.
Although I’ve given a number of metrics you should start by identifying between 2 and 5 metrics in each ecosystem level. I also try to map lower-level metrics to metrics in the ecosystem above in order to ensure that a metric is driving the desired behaviour.
Building a responsive culture
Lastly, none of these techniques can be implemented effectively without a culture that embraces, seeks out, and thrives on change. The typical characteristics of this type of culture are all the things you see in agile and lean books/courses:
- No blame culture
- Empowerment of teams/individuals
- Delegating responsibility and authority for entire problems to teams
- Smaller teams to reduce communication networks
- Clear, high-level targets/goals with clear measurable objectives (see ‘Fast appropriate feedback’)
- etc.
However, I think it’s important to emphasise this culture is something that needs to be pervasive throughout the whole organisation. It’s all very well having a software development team or department that has this culture but if the rest of the organisation interfacing with that group is in a strictly hierarchical command and control culture this will cause friction and ultimately be much less effective in responding to change. So what do you do if the organisation is not on board with this culture?
Ideally you can convince the ‘C’ level management and the board that this culture is required and demonstrate how to achieve it through some ‘localised’ success by adopting some of the strategies suggested.
However, I have found some success in tying the metrics that the ‘C’ level management look at, which tend to be either in the organisational/department environment or world wide/market environment, to the metrics in the ecosystems below to show how ‘moving the needle’ in one metric impacts the others. I’ve also found that this helps start the conversation about software not being a ‘cost’ to the organisation but it’s primary means of revenue generation in the future for most organisations. Demonstrating that software is not only about automating processes but about creating new ways to interact with customers in new markets. This in turn can provoke a move away from project focused development towards product/platform focused development.
If you’re trying to convince the upper management/board of something, demonstrating how it impacts the metrics they care about is hugely powerful.
Summary
I’ve covered a lot of ground in this post. However, if there are only three things you take away from this I hope they would be:
- Pick a couple of properties in each ecosystem that you wish to change and identify metrics for them (preferably linking lower level metrics with those higher up the ecosystems ‘ladder’)
- Pick a couple of ‘constraints’ that you don’t yet implement that might help support the required changes above and think about how to implement those constraints
- Use the constraints you pick to guide the ‘materials’ you use and the ‘culture’ you need. For example, if you want to deal with changes in data/message structure more effectively you may decide to concentrate on structural typing and accretion only approaches to interfaces and data storage. This might lead you to picking certain languages/libraries that support structural typing, easy parsing of data, tolerant reader pattern and immutable databases.
There’s no one-size-fits-all solution when it comes to evolutionary architecture. Instead, it’s important to gather feedback over an appropriate timescale, adjust your approaches as you learn and grow, and don’t try to change everything all at once. I hope this post has given you some food for thought and a few practical approaches to try.




Leave a comment